
La migration Salesforce zéro perte de données est présentée comme un objectif standard dans tous les appels d’offres. En pratique, c’est l’un des engagements les plus mal compris; et les plus mal exécutés; de l’écosystème.
Le problème n’est pas technique au sens strict. Les outils existent. L’architecture est documentée. Ce qui échoue systématiquement, c’est la gouvernance des décisions prises en amont, avant que la première ligne de code de migration soit écrite.
Pourquoi “zéro perte” ne signifie pas ce que vous croyez
Dans les migrations impliquant plus de 8 millions d’enregistrements répartis sur 7 systèmes legacy; un volume courant dans les ETI ayant accumulé des années de dette technique; la notion de “perte de données” recouvre en réalité trois phénomènes distincts qu’il faut traiter séparément.
La perte physique d’abord : un enregistrement présent en source qui n’existe plus en cible. C’est le cas le plus visible, le plus facile à détecter avec un simple comptage différentiel.
La perte sémantique ensuite : l’enregistrement est présent, mais sa signification métier a changé. Un champ Status mappé de façon incorrecte, une relation parent-enfant inversée, une devise mal convertie. Ces erreurs passent les contrôles de volumétrie et ne sont détectées qu’en production, souvent par les utilisateurs finaux.
La perte de contexte enfin : les données sont là, les valeurs sont correctes, mais les métadonnées associées; historique de modification, propriétaire, date de création originale; ont été écrasées ou perdues. Dans un contexte RGPD, c’est potentiellement un problème de conformité, pas seulement un problème de qualité.
Une migration Salesforce zéro perte de données réelle doit adresser les trois dimensions. La plupart des projets n’adressent que la première.
L’architecture qui fonctionne réellement
Le pattern qui tient à l’échelle repose sur quatre couches distinctes, non négociables.
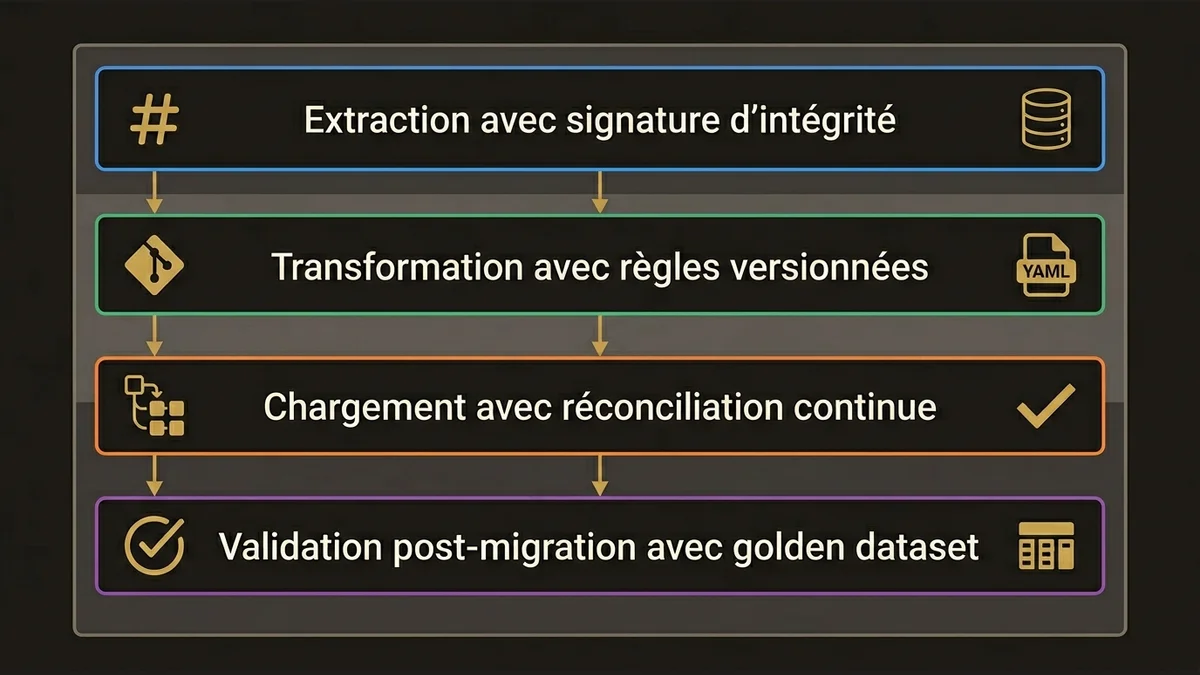
Extraction avec signature d’intégrité. Chaque enregistrement extrait de la source doit être accompagné d’un hash calculé sur les champs critiques. Ce hash sera recalculé en cible après chargement pour détecter toute altération silencieuse. MuleSoft est l’outil naturel pour cette couche dans l’écosystème Salesforce; il permet d’orchestrer l’extraction, de calculer les signatures et de journaliser les anomalies dans un pipeline traçable.
Transformation avec règles versionnées. Les règles de mapping ne doivent pas vivre dans des scripts ad hoc. Elles doivent être versionnées, revues par le métier et auditables. Un fichier de configuration YAML versionné dans Git, validé par le product owner métier, vaut mieux que 200 lignes de transformation Apex non documentées. En pratique, les projets qui échouent sur la perte sémantique ont presque toujours des règles de transformation qui vivent dans la tête d’un consultant.
Chargement avec réconciliation continue. Le chargement ne se valide pas à la fin. Il se valide en continu, par batch, avec un rapport de réconciliation généré après chaque lot. Le seuil d’erreur acceptable doit être défini contractuellement avant le début du projet; pas découvert en go-live. Un taux d’erreur de 0,1% sur 8 millions d’enregistrements représente 8 000 enregistrements corrompus. C’est inacceptable dans la plupart des contextes métier.
Validation post-migration avec golden dataset. Avant toute bascule en production, un ensemble d’enregistrements représentatifs; le “golden dataset”; doit être validé manuellement par des référents métier. Ce dataset doit couvrir les cas limites : enregistrements avec des relations complexes, des champs multi-valués, des historiques longs. La validation automatisée ne suffit pas pour détecter les pertes sémantiques.
Les trois erreurs qui compromettent la migration
L’erreur la plus fréquente est de traiter la migration comme un projet technique isolé. Dans les organisations avec des équipes Salesforce de taille significative, la migration touche invariablement des automatisations Flow, des règles de validation, des profils de sécurité et des intégrations externes. Migrer les données sans auditer ces dépendances en amont, c’est garantir des comportements inattendus en production. Un enregistrement Account migré correctement peut déclencher une Flow qui échoue parce que le champ RecordType a changé de nom dans la nouvelle org.
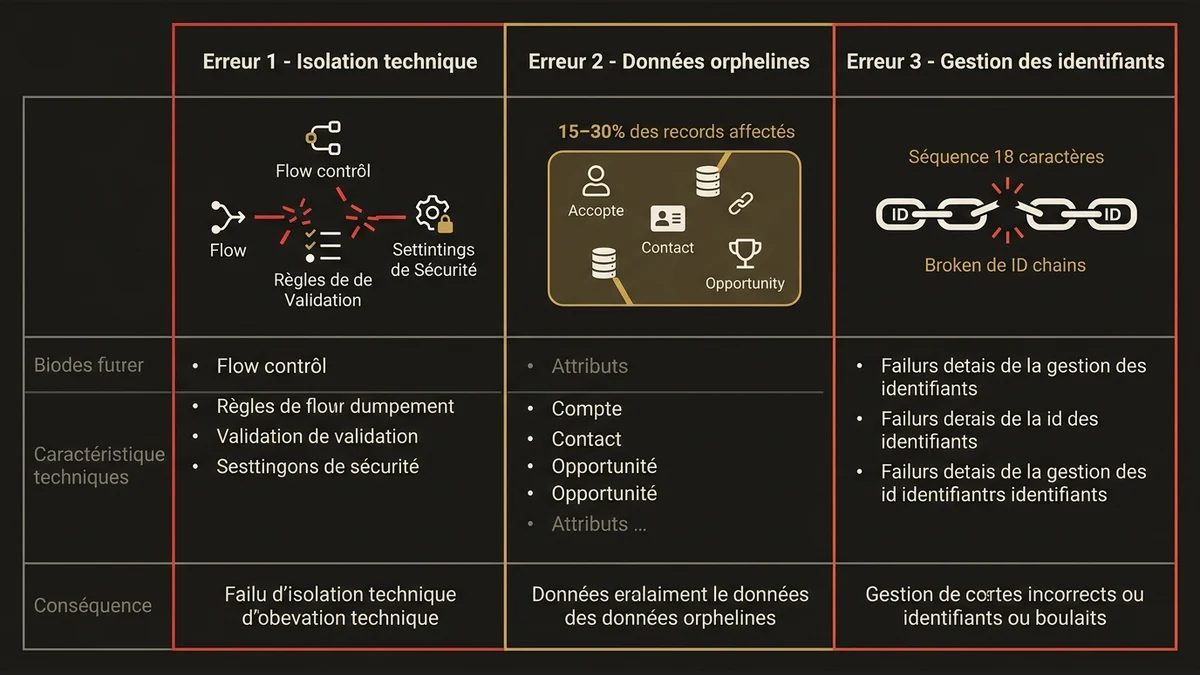
La deuxième erreur est de sous-estimer le volume des données orphelines. Dans toute org Salesforce ayant plus de cinq ans d’existence, une fraction significative des enregistrements; souvent entre 15% et 30%; sont des données orphelines : des contacts sans Account, des opportunités sans propriétaire actif, des tâches liées à des enregistrements supprimés. Ces données ne peuvent pas être migrées telles quelles. Elles nécessitent une décision métier explicite : archivage, suppression, rattachement à un enregistrement générique. Cette décision prend du temps et doit être prise avant le début de la migration, pas pendant.
La troisième erreur concerne la gestion des identifiants. Salesforce génère des IDs de 18 caractères qui ne sont pas portables entre orgs. Toute relation entre enregistrements doit être reconstituée via des clés externes métier; un numéro de client, un code produit, un identifiant contrat. Si ces clés externes n’existent pas ou ne sont pas fiables dans la source, la migration des relations est impossible sans une phase de nettoyage préalable. Les projets qui découvrent ce problème en phase de chargement perdent systématiquement plusieurs semaines.
Pour aller plus loin sur la gestion de la dette technique qui précède souvent ces migrations, l’article sur le framework d’audit de dette technique Salesforce détaille les patterns d’accumulation les plus courants.
Le framework décisionnel avant de commencer
Avant d’écrire la moindre requête SOQL d’extraction, quatre questions doivent avoir une réponse documentée et validée par le sponsor métier.
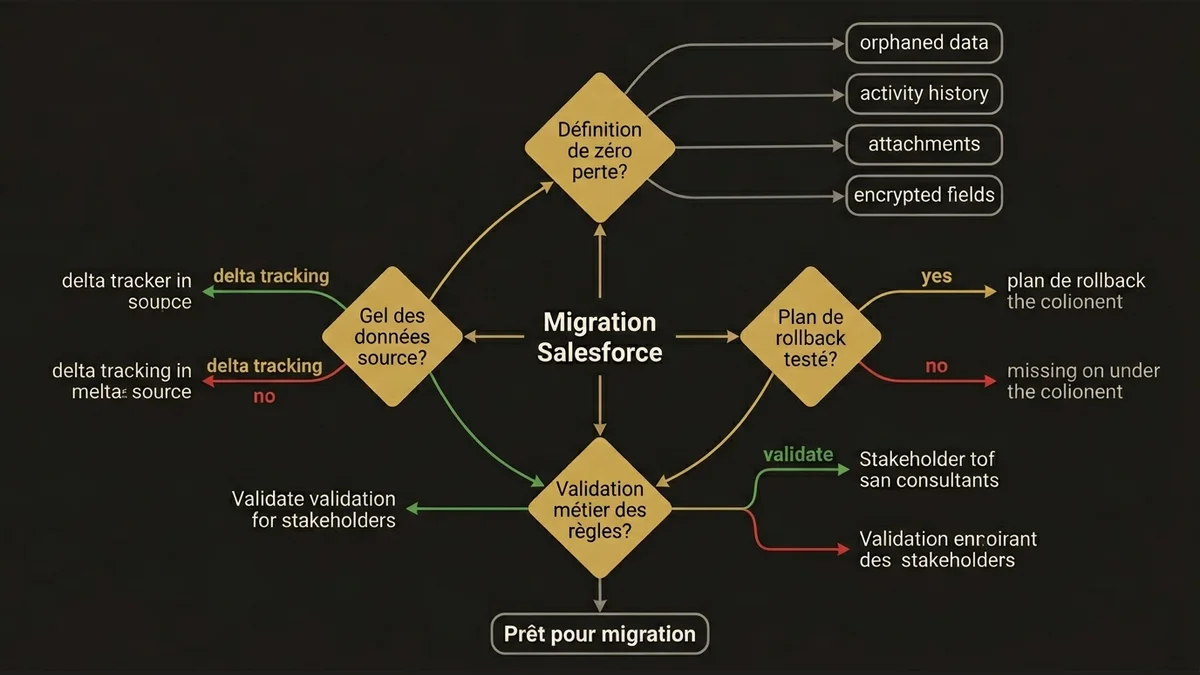
Quelle est la définition contractuelle de “zéro perte” ? Inclut-elle les données orphelines ? Les historiques d’activité ? Les fichiers attachés ? Les champs chiffrés ? La réponse à cette question détermine le périmètre réel du projet et son budget.
Quel est le plan de rollback ? Si la migration échoue à 60% du chargement, quelle est la procédure pour revenir à l’état initial ? Cette procédure doit être testée en environnement sandbox avant le go-live. Les migrations sans plan de rollback testé sont des paris, pas des projets.
Qui valide les règles de transformation métier ? Un architecte solution peut proposer un mapping, mais la validation doit venir d’un référent métier qui comprend la signification des données. Sans cette validation, les pertes sémantiques sont inévitables.
Quel est le calendrier de gel des données source ? Pendant la migration, la source doit être en lecture seule ou les modifications doivent être tracées pour être rejouées en cible. Sans gel ou sans mécanisme de delta, les données migrées sont obsolètes dès le lendemain du chargement.
Outillage et automatisation : ce qui est réellement utile
Data Cloud peut jouer un rôle dans les migrations complexes, mais pas de la façon dont il est souvent présenté. Son utilité réelle n’est pas dans le chargement des données; c’est le rôle de MuleSoft ou des outils ETL classiques. Elle est dans la phase de validation post-migration, via les Data Streams et les capacités d’Identity Resolution pour détecter les doublons créés par la migration et valider la cohérence des profils unifiés.
Pour les migrations impliquant des données client, l’Identity Resolution avec ses rulesets de correspondance permet de détecter les cas où un même client a été migré deux fois avec des variantes de nom ou d’adresse. C’est une validation que les outils de comptage différentiel ne peuvent pas faire.
Les outils de migration tiers; Dataloader.io, Apsona, ou les connecteurs MuleSoft natifs Salesforce; sont tous capables d’assurer la couche de chargement. Le choix de l’outil est moins important que la rigueur du processus qui l’entoure. Un projet qui utilise un outil basique avec un processus rigoureux surpasse systématiquement un projet qui utilise un outil sophistiqué sans gouvernance.
Pour les architectes qui interviennent sur des migrations en difficulté, la page /services/org-health-recovery détaille les patterns d’intervention sur des projets en détresse.
Points Clés
- Une migration Salesforce zéro perte de données adresse trois dimensions distinctes : perte physique, perte sémantique et perte de contexte. La plupart des projets ne gèrent que la première.
- Les règles de transformation doivent être versionnées et validées par le métier avant le début du chargement; pas découvertes en cours de projet.
- Dans les orgs de plus de cinq ans, entre 15% et 30% des enregistrements sont typiquement orphelins et nécessitent une décision métier explicite avant migration.
- La gestion des identifiants Salesforce (IDs non portables entre orgs) est le problème technique le plus sous-estimé : sans clés externes métier fiables, la migration des relations est bloquée.
- Un plan de rollback testé en sandbox est non négociable. Une migration sans rollback validé est un pari sur la réussite du premier essai.
Need help with org health & recovery architecture?
Diagnose failing Salesforce implementations, eliminate technical debt, and architect recovery plans that get derailed projects back on track within 90 days.
Related Articles

Gouvernance Salesforce : le framework qui tient
Sans salesforce gouvernance framework entreprise structuré, la dette technique s'accumule silencieusement. Voici l'architecture de gouvernance qui résis...

Salesforce Org Health Check Assessment Guide
Most Salesforce health checks miss the risks that actually kill projects. Here's the architectural framework that surfaces what matters.
Salesforce Technical Debt: Acceptable Levels
Not all Salesforce org technical debt is worth fixing. Learn how to classify debt by risk tier and decide what to remediate versus tolerate.